MAJ 04/2024 : La fonction CROISER.AVEC a été renommée PIVOTER.PAR.
MAJ 05/2024 : Ajout des arguments Value_sort_method dans la fonction GROUPER.PAR et Relative_to dans PIVOTER.PAR.
MAJ 05/2024 : L'argument Value_sort_method dans la fonction GROUPER.PAR est déplacé en dernière position et renommé Fields_relationship.
MAJ 08/2024 : La fonction semble être disponible pour les utilisateurs Insider Current Channel.
Après 60 jours d'attente (nouveauté 11/2023), j'accède enfin à ces nouveaux "jouets" et peut enfin vous les présenter.
A moment où j'écris cet article, ce sont toujours des fonctions expérimentales/en test susceptibles d'être modifiées en version finale.
Ces nouvelles fonctions vont nous permettre de faire du croisement/agrégation de données comme via les tableaux croisés dynamiques.
Le terme "Croisement de données" m'a toujours paru inapproprié, il s'agirait plus de tableaux synthèses, de tableau faisant une agrégation de valeurs car il n'y a pas toujours des "croisements".
Les gros avantages de ces fonctions par rapport au tableau croisé dynamique sont :
- Plus de liberté dans le choix de l’opération d’agrégation.
- Une mise à jour automatique/dynamique du tableau. Celui-ci étant généré par une formule (Voir Formules de tableaux dynamiques, une nouvelle logique de conception).
La fin des tableaux croisés dynamiques ?
Contrairement à certain titre accrocheur que l'on peut lire sur la toile, je ne pense pas que ce soient leurs fins.
Ceux-ci ont encore de nombreux avantages notamment en termes de facilité de structuration, de mise en forme et de puissance de traitement.
De plus via PowerPivot on peut réaliser beaucoup plus de choses.
Vu que ces fonctions sont récentes, il m'est pour l'instant difficile d'évaluer leurs réels intérêts après avoir passé la 1ere bonne impression.
Dans ce premier article je vais présenter la structure générale de ces fonctions puis je posterais un second article pour comparer les fonctionnalités qu'elles offrent par rapport à celles des tableaux croisés dynamiques (voir : Fonction PIVOTER.PAR (PIVOTBY) Vs Tableau croisé dynamique).
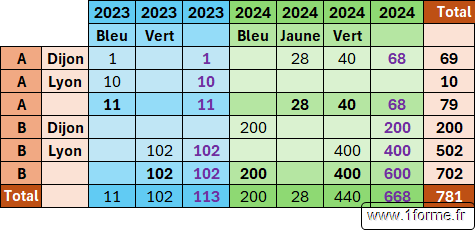
Base de données de départ
Tout comme les tableaux croisés dynamiques on travaille à partie de base de données Excel en tableau structuré ou non.
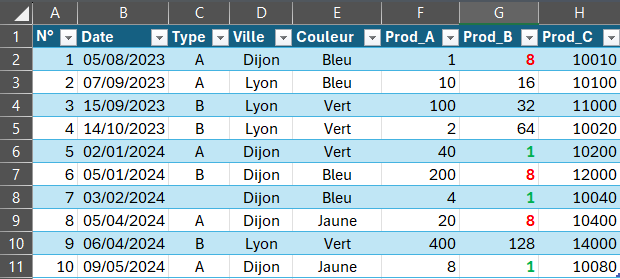
On peut imaginer que ce sont les volumes de vente de 3 produits en fonction du type, de la date et de la couleur.
La fonction GROUPER.PAR (GROUPEBY)
Rôle
Générer une synthèse en regroupant les lignes ayant des "catégories" identiques et en appliquant une fonction de calcule aux valeurs correspondantes.
Exemple d'illustration
Syntaxe
Edit : Les noms arguments ont changés plusieurs fois.
= GROUPER.PAR(Row_fields ; Values ; Functiοn ; [Field_headers] ; [Total_Treatement] ; [Sort_order] ; [Filter_array] ; [Field_relationship])- Row_fields : Plage ou tableau des champs utilisées en étiquette de ligne.
- Values : Plage ou tableau des champs utilisées en tant que valeur à synthétiser/agréger.
- Function : Fonction ou tableau de fonctions utilisé sur le(s) champ(s) de Valeur (SOMME, MOYENNE, LAMBDA...).
- [Field_headers] : Paramètre de prise en compte des étiquettes pour les champs de Row_fields et Valeurs.
- Non précisé : Détection automatique d'étiquette (ne semble pas bien fonctionner).
- 0 : Non (la 1ere ligne sera prise comme une donnée/reprise dans les étiquettes de ligne).
- 1 : Oui mais non affichée (la 1ere ligne ne sera pas prise comme une donnée/non reprise dans les étiquettes de ligne).
- 2 : Non mais affichée (Excel affichera alors Champ de ligne 1, Champ de ligne 2...).
- 3 : Oui mais affichée (utilise les valeurs de la 1ère ligne).
- [Total_Treatement] : Paramètre d'affichage des Totaux généraux et Sous-totaux.
- Non précisé : Mode automatique. Selon l'aide Totaux généraux et Sous-totaux s'il y a au moins 2 niveaux d'étiquette de ligne, c'est à dire au moins 2 champs dans Row_fiel (ne semble pas bien fonctionner).
- 0 : Aucun total.
- 1 : Totaux généraux en dessous des valeurs (pour la colonne entière).
- 2, 3, 4... : Totaux généraux et Sous-totaux en dessous des valeurs. La valeur indique le nombre de niveaux à activer (À condition d'un nombre suffisant de niveaux d'étiquette de ligne c'est à dire de champs dans Row_fiel).
- -1, -2, -3... : Identique à 1, 2, 3... mais place les Totaux généraux et Sous-totaux en haut des valeurs.
- [Sort_order] : Valeur ou matrice de valeurs indiquant le(s) n° de/des colonne(s) sur le/les quelle(s) appliquer un tri (positif = croissant, négatif décroissant).
- [Filter_array] : Matrice de valeurs booléennes ou la valeur VRAI représente les lignes à conserver.
- [Field_relationship] : Respect de la hiérarchie des champs lors du tri des valeurs de l'argument Valeur (Total_Treatement doit être Non précisé, 0 ou 1).
- Non précisé ou 0 : Mode Hiérarchique.
- 1 : Tableau.
Illustrations de l'utilisation des différents arguments
Remarque : Les exemples suivants utilisent la notation structurés (exemple : BDD[[#Tout];[Ville]]) mais fonctionneraient avec des références de cellules classiques (exemple : D1:D11).
La syntaxe la plus basique servant de point de départ
On utilise que les 3 premiers arguments, un seul champ en ligne (les villes) et en valeur (les produits A) et une seule fonction (ici la somme).
=GROUPER.PAR(BDD[[#Tout];[Ville]];BDD[[#Tout];[Prod_A]];SOMME)
Argument Row_fields
Plage ou tableau des champs utilisées en étiquette de ligne.
Utilisation de plusieurs champs pour Row_fields
Cas de colonnes consécutives
=GROUPER.PAR(BDD[[#Tout];[Ville]:[Couleur]];BDD[[#Tout];[Prod_A]];SOMME)Il suffit de sélectionner les colonnes (BDD[[#Tout];[Ville]:[Couleur]] ou D1: E11).
Cas de colonnes non consécutives
=GROUPER.PAR(ASSEMB.H(BDD[[#Tout];[Type]];BDD[[#Tout];[Couleur]]);BDD[[#Tout];[Prod_A]];SOMME)On va utiliser la fonction ASSEMB.H( Plage1 ; Plage 2 ...) pour générer un tableau.
Modification des valeurs des champs d'entête de ligne
On peut directement appliquer des fonctions aux champs de Row_fields.
Exemple 1 : Regroupement/Agrégation par année
=GROUPER.PAR(ANNEE(BDD[Date]);BDD[Prod_A];SOMME)
Exemple 2 : Regroupement par mois et année
Contrainte : On ne veut qu'une colonne en résultat pour les étiquettes de ligne (pas une colonne Mois et une 2eme colonne Année).
=GROUPER.PAR(DATE(ANNEE(BDD[Date]);MOIS(BDD[Date]);1);BDD[Prod_A];SOMME)
Remarque : Utiliser TEXTE(BDD[Date];"mmm aaaa") poserait de problème d'ordre de tri pour les mois.
Argument Valeurs
Plage ou tableau des champs utilisées en tant que valeur à synthétiser/agréger.
=GROUPER.PAR(BDD[Ville];BDD[[Prod_A]:[Prod_B]];SOMME)
=GROUPER.PAR(BDD[Ville];ASSEMB.H(BDD[Prod_A];BDD[Prod_C]);SOMME)Il suffit de sélectionner les colonnes ou passer là aussi par la fonction ASSEMB.H si les colonnes ne sont pas consécutives.
Argument Fonction (d'agrégation)
Fonction ou tableau de fonctions utilisé sur le(s) champ(s) de Valeur.
On peut utiliser une des 16 fonctions proposées par défaut (SOMME, POUCENTAGE.DE, MOYENNE, MEDIANE, NB, NBVAL, MAX, MIN, PRODUIT, TABLEAU.EN TEXTE, CONCAT, ECARTYPE.STANDARD, ECARTYPE.PEARSON, VAR.S, VAR.P.N, MODE.SIMPLE) ou une fonction LAMBDA personnalisées.
Ce qui peut étonner un utilisateur averti d'Excel c'est la saisie directe du nom de la fonction en forme de texte SANS GUILLEMETS !
Jusqu'ici on utilisait des codes numériques (1, 2, ...) pour désigner les fonctions de calcul dans les autres fonctions d'Excel (Comme SOUS.TOTAL, AGREGAT...).
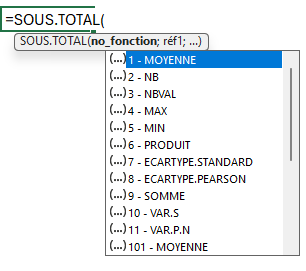
Il s'agit en fait de nouveaux raccourcis spécifiques aux fonctions LAMBDA (appelés "eta reduced lambda", je vous laisse le soin de la traduction 😊).
Ils sont utilisables aussi dans les fonctions corolaires à la fonction LAMBDA (Voir Les fonctions liées à LAMBDA).
Ainsi :
=GROUPER.PAR(BDD[[#Tout];[Ville]];BDD[[#Tout];[Prod_A]];SOMME)est la forme abrégé de
=GROUPER.PAR(BDD[[#Tout];[Ville]];BDD[[#Tout];[Prod_A]];LAMBDA(v;SOMME(v)))Utiliser une des 16 fonctions proposées
Les fonctions SOMME, MOYENNE, MEDIANE, NB, NBVAL, MAX, MIN, PRODUIT, ECARTYPE.STANDARD, ECARTYPE.PEARSON, VAR.S, VAR.P.N sont classiques, je ne vais pas m'attarder dessus.
POUCENTAGE.DE
Nouvelle fonction Excel, pouvant être utilisée en dehors de la fonction GROUPER.PAR, facilitant le calcul de pourcentage (Elle divise la somme d'un échantillon de valeurs par la somme des valeurs).
Exemple :
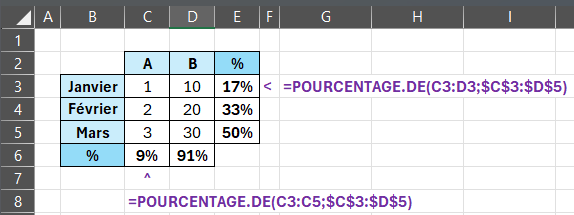
=GROUPER.PAR(BDD[[#Tout];[Ville]];BDD[[#Tout];[Prod_A]];POURCENTAGE.DE)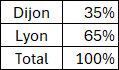
CONCAT
=GROUPER.PAR(BDD[[#Tout];[Ville]];BDD[[#Tout];[Couleur]];CONCAT)
On remarque un intrus (Étiquette Ville). Pour pallier ce problème, soit ne pas sélectionner les étiquettes de colonne, soit masquer les étiquettes avec l'argument Field_headers à 1.
TABLEAU.EN TEXTE
=GROUPER.PAR(BDD[[#Tout];[Ville]];BDD[[#Tout];[Couleur]];TABLEAU.EN.TEXTE)
On remarque là aussi l'intrus Ville.
MODE.SIMPLE
Rappel : Cette fonction renvoie la valeur la plus fréquente.
=GROUPER.PAR(BDD[[#Tout];[Ville]];BDD[[#Tout];[Prod_B]];MODE.SIMPLE)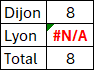
Remarques :
- Pour Dijon, les valeurs 8 et 1 se répètent 3 fois chacune et Excel choisit 8 (il semble que ce soit la première valeur trouvée et non le premier triplon trouvé).
- Pour Lyon, il n'y a pas de répétition de valeurs d'où #N/A.
Utiliser une fonction personnalisée
Dans l'exemple de la fonction TABLEAU.EN TEXTE, on voit des répétions de la même valeur de Couleur. Créons une fonction pour éviter l'apparition de ces doublons.
=GROUPER.PAR(BDD[[#Tout];[Ville]];BDD[[#Tout];[Couleur]];LAMBDA(x; TABLEAU.EN.TEXTE(UNIQUE(x))))
Remarque :
- Définir la fonction LAMBDA dans le Gestionnaire de noms permet de l'utiliser via son nom comme les 16 fonctions prédéfinies.
Utilisation de plusieurs fonctions
Une possibilité qui ne semble pas avoir été remarquée pour l'instant dans les articles traitant ce cette fonction.
Présentation en lignes
Avec une fonction ASSEMB.V.
=GROUPER.PAR(BDD[[#Tout];[Ville]];BDD[[#Tout];[Prod_A]];ASSEMB.V(SOMME;MOYENNE);0)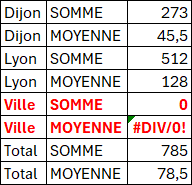
Présentation en colonnes
Avec une fonction ASSEMB.H.
=GROUPER.PAR(BDD[[#Tout];[Ville]];BDD[[#Tout];[Prod_A]];ASSEMB.H(SOMME;MOYENNE);0)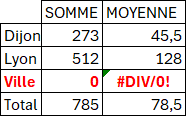
Remarques :
- L'erreur #DIV/0 ! vient encore de l'étiquette intruse (Rappel : facilement masquée avec l'argument Field_headers à 1) !
- En cas d'utilisation de fonctions LAMBDA, Excel génère comme intitulé de lignes/colonnes le texte "PERSONNALISÉ" et ce même en passant pas une définition dans le Gestionnaire de noms.
Argument Field_headers
Paramètre de prise en compte des étiquettes pour les champs de Row_fields et Valeurs.
Dans les exemples avec les fonctions CONCAT, TABLEAU.EN TEXTE ou la fonction personnalisée LAMBDA, l'étiquette Ville était présente.
Nous pouvons passer Field_headers à 1 pour ne pas l'afficher.
=GROUPER.PAR(BDD[[#Tout];[Ville]];BDD[[#Tout];[Couleur]];LAMBDA(x; TABLEAU.EN.TEXTE(UNIQUE(x)));1)Argument Total depht
Paramètre d'affichage des Totaux généraux et Sous-totaux.
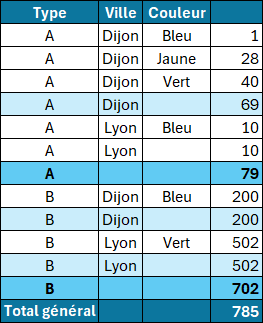
=GROUPER.PAR(BDD[[#Tout];[Type]:[Couleur]];BDD[[#Tout];[Prod_A]];SOMME;3;3)Ici paramétré à 3 pour avoir des sous-totaux pour Type et Ville.
Avec la valeur 2 les sous totaux pour Ville, en bleu clair, ne seraient pas présent (A-Dijon=69, A-Lyon=10 (couleur manquante), B-Dijon=200, B-Lyon=502).
Argument Sort_order
Valeur ou matrice de valeurs indiquant le(s) n° de/des colonne(s) sur le/les quelle(s) appliquer un tri (n° positif = tri en ordre croissant, n° négatif = tri en ordre décroissant).
Il semble y avoir un tri par défaut en ordre croissant sur les étiquettes.
Forçage en tri décroissant sur la 2ème colonne en utilisant la valeur -2.
=GROUPER.PAR(BDD[[#Tout];[Ville]:[Couleur]];BDD[[#Tout];[Prod_A]];SOMME;;;-2)
Forçage en tri décroissant sur la 1ère et 2ème colonne en utilisant la matrice {-1 ; -2}.
Remarque : {-2 ; -1} fonctionne aussi donc on peut en déduire que la colonne de gauche est toujours prioritaire sur celle de droite).
=GROUPER.PAR(BDD[[#Tout];[Ville]:[Couleur]];BDD[[#Tout];[Prod_A]];SOMME;;;{-1;-2})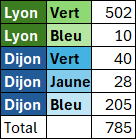
Argument Filter_array
Matrice de valeurs booléennes ou la valeur VRAI représente les lignes à conserver.
Cet argument fonctionne comme l'argument Inclure de la fonction FILTRE (voir L'impressionnante fonction de calcul FILTRE).
=GROUPER.PAR(BDD[[#Tout];[Ville]];BDD[[#Tout];[Prod_A]];SOMME;;;;;ANNEE(BDD[[#Tout];[Date]])=2024)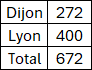
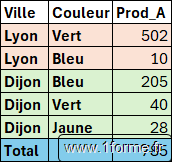
Argument Field_relationship
Argument ajouté en 05/2024, modifier 05/2024.
Ne fonction que pour un tri basé sur les champs de l'argument Valeur. Total_treatement doit être Non précisé, 0 ou 1.
Field_relationship non précisé
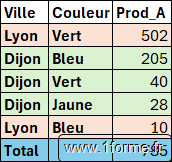
Field_relationship à 1
Exemples de combinaison avec d'autres fonctions
Filtrer le résultat de l'agrégation
On va appliquer une fonction FILTRE.
Devant faire référence au résultat de GROUPER.PAR deux fois, on va le mémoriser via une fonction LET. On accède à la colonne servant de base à la fonction FILTRE via la fonction INDEX.
=LET(t;GROUPER.PAR(BDD[[#Tout];[Ville]:[Couleur]];BDD[[#Tout];[Prod_A]];SOMME);
FILTRE(t;INDEX(t;;3)>30))
Grouper en colonne et non en ligne
On va simplement utiliser la fonction TRANSPOSE.
=TRANSPOSE(GROUPER.PAR(BDD[[#Tout];[Ville]];BDD[[#Tout];[Prod_A]];SOMME))
La fonction PIVOTER.PAR (PIVOTBY)
Il s'agit d'une version plus évoluée que GROUPER.PAR pouvant travailler en ligne, en colonne ou les deux.
Ayant déjà vu GROUPER.PAR les explications seront réduit (un 2éme article à venir comparant PIVOTER.PAR avec les tableaux croisés dynamiques fournira de nombreux exemples d'utilisation de cette fonction).
Voir : Fonction PIVOTER.PAR (PIVOTBY) Vs Tableau croisé dynamique
Rôle
Même rôle que GROUPER.PAR, se rapprochant encore plus des tableaux croisés dynamiques.
Syntaxe
=PIVOTER.PAR(Row_fields ; Col_fields ; Values ; Functiοn ; [Field_headers] ;
[Row_total_depth] ; [Row_sort_order] ;
[Col_total_depth] ; [Col_sort_order] ; [Filter_array] ; [Relative_to])On retrouve des arguments communs avec GROUPER.PAR.
- Row_fields, Valeurs, Fonction, [Field_headers], [Filter_array] : Ce sont les mêmes arguments que GROUPER.PAR.
- Col_fields : Plage ou tableau des champs utilisées en étiquette de colonne. Tout comme Row_fields, il n'est pas réellement obligatoire, tant que l'un des deux est indiqué.
- [Row_total_depth], [Col_total_depth], [Row_sort_order], [Col_sort_order] : Ce sont les arguments correspondants à [Total_depth], [Sort_order] pour les lignes et les colonnes.
Nouvel argument ajouté en 05/2024 :
- [Relative_to] : N'impacte que les résultats de la fonction POURCENTAGE.DE.
- Non précisé ou 0 : Par rapport au total des colonnes.
- 1 : Par rapport au total des lignes.
- 2 : Par rapport au total général.
- 3 : Par rapport au total de la colonne parente (en ligne !). Nécessite au moins 2 valeurs dans Row_fields.
- 4 : Par rapport au total de la ligne parente (en colonne !). Nécessite au moins 2 valeurs dans Col_fields.
Exemple 1
=PIVOTER.PAR(BDD[[#Tout];[Type]:[Ville]];
ASSEMB.H(ANNEE(BDD[[#Tout];[Date]]);BDD[[#Tout];[Couleur]]);BDD[[#Tout];[Prod_A]];SOMME;;;;;;
BDD[[#Tout];[Type]]<>"")
La partie filtre BDD[[#Tout];[Type]]<>"" permet de supprimer la ligne générée par la valeur vide en C8 dans la base de données.
Remarque :
- Si seul l'argument Row_fields est précisé, Col_fields laissé vide, on obtient le même résultat qu'avec la fonction GROUPER.PAR(...).
- Si seul l'argument Col_fields est précisé, Row_fields laissé vide, on obtient le même résultat qu'avec la formule TRANSPOSE(GROUPER.PAR(...)).
=PIVOTER.PAR(BDD[[#Tout];[Ville]];;BDD[[#Tout];[Prod_A]];SOMME)
=PIVOTER.PAR(;BDD[[#Tout];[Ville]];BDD[[#Tout];[Prod_A]];SOMME)Argument Relative_to
Valeur 0 ou omis (Colonne)
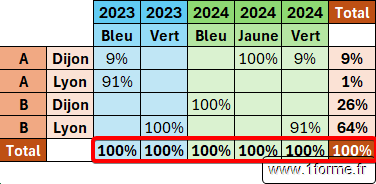
Valeur 1 (Ligne)
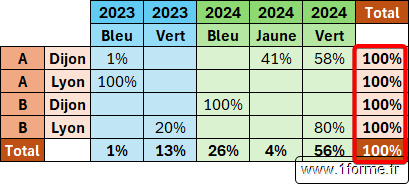
Valeur 2 (Total)
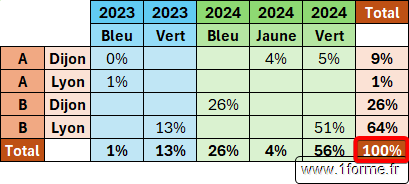
Ajout de sous totaux :
SOMME avec sous totaux
Valeur 3 (Total colonne parente)
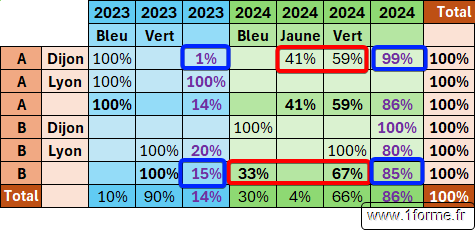
Valeur 4 (Total ligne parente)
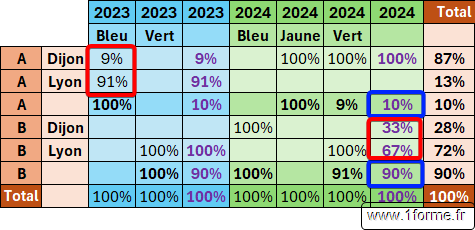
Exemple 2
Présentation en colonne de 2 fonctions personnalisées avec tri et personnalisation des étiquettes.
Tableau de départ
Nommé TabVentes
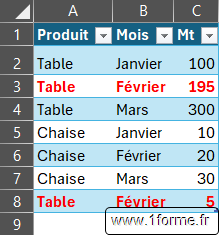
Résultat
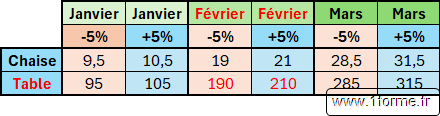
Formule
= LET(
m5pc ; LAMBDA(v ; 0,95 * SOMME(v));
p5pc ; LAMBDA(v ; 1,05 * SOMME(v));
MesLambda ; ASSEMB.H( m5pc ; p5pc);
TC ; SUBSTITUE(SUBSTITUE(
PIVOTER.PAR(TabVentes[Produit];TabVentes[Mois];TabVentes[Mt];MesLambda;0;0;;0);
"PERSONNALISÉ1";"-5%");
"PERSONNALISÉ2";"+5%");
TRIERPAR(TC ; EQUIV(CHOISIRLIGNES(TC ; 1) ; {"";"Janvier";"Février";"Mars"} ; 0) ; 1))Interprétation de la formule
- m5pc : Somme des valeurs diminuées de 5%.
- p5pc : Somme des valeurs augmentées de 5%.
- MesLambda : Matrice de 2 colonnes.
- TC : Tableau croisé généré par la fonction PIVOTER.PAR sans totaux.
- On remplace les intitulés "PERSONNALISÉ1" et "PERSONNALISÉ2" (générés automatiquement) par les textes "-5%" et "+5%" via des fonctions SUBSTITUE.
- Résultat : Afin de classer les colonnes (les noms des mois) en ordre calendaire et non alphabétique, on applique un tri en colonne basé sur les valeurs de la ligne 1 (via CHOISIRLIGNES renvoyant une matrice en colonne).
- Les mois ne devant pas être en ordre alphabétique, on les substitue à leur position dans une matrice de référence (la valeur "" est pour gérer le cas de la 1ere colonne ne contenant pas d'étiquette de mois). Un simple tri en ordre croissant sur la matrice résultante donne l'ordre désiré.
Merci pour votre attention bienveillante.
Il semble que la fonction CROISER.AVEC soit devenue PIVOTER.PAR! (version française)...
(Merci pour votre travail)
Merci pour cette information, je ne l'avais pas remarqué.