- Base de données de départ
- Disposition des étiquettes de ligne et de colonne
- Disposition des résultats de synthèse
- Disposition globale
- Mise en forme du tableau
- Création de regroupements personnalisés
- Les fonctions de synthèses
- Simulation des modes d'affichage des valeurs
- Personnalisation étiquettes
- Utilisation des segments pour appliquer un filtre
- Divers
MAJ 04/2024 : La fonction CROISER.AVEC a maintenant pour nom PIVOTER.PAR.
MAJ 05/2024 : Ajout de l'arguments Relative_to dans la fonction PIVOTER.PAR
Dans ce premier article (Voir Les nouvelles fonctions GROUPER.PAR (GROUPEBY) et PIVOTER.PAR (PIVOTBY)) j'ai présenté les fonctions GROUPER.AVEC (GROUPBY) et PIVOTER.PAR (PIVOTBY).
Le but de ce 2eme article est de tenter de reproduire les possibilités offertes par les tableaux croisés dynamiques au moyen de la fonction PIVOTER.PAR.
C'est aussi l'excuse de pousser un peu plus loin les manipulations et résultats que nous permet cette fonction.
Cette fonction étant très récente et sujette à évolution, il faut prendre cet article comme une "ébauche", n'ayant pas non plus d'expérience sur son utilisation.
Base de données de départ
Une base de données un peu plus conséquente que pour le premier article permettant plus de manipulations.

Disposition des étiquettes de ligne et de colonne
Positionnement des champs en Ligne, Colonne, Valeur.
- En ligne (Row_fields) : Contrat, Civilité2, Service.
- En colonne (Col_fields) : Ville, Classification.
- En valeur (Fonction) : Moyenne et NBVAL de Salaire et Nb_Enfants.
=PIVOTER.PAR(
ASSEMB.H(
Tableau1[[#Tout];[Contrat]];
Tableau1[[#Tout];[Civilite2]];
Tableau1[[#Tout];[Service]]);
ASSEMB.H(
Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Classification]]);
ASSEMB.H(
Tableau1[[#Tout];[Salaire]];
Tableau1[[#Tout];[Nb_Enfants]]);
ASSEMB.H(MOYENNE;NBVAL))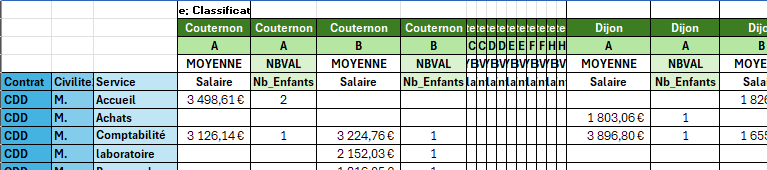
Le but ici étant de tester les possibilités de la fonction mais bien évidemment un tel tableau est illisible car trop complexe.
Disposition des résultats de synthèse
Positionnement des champs Valeur en horizontal/vertical.
En horizontal/colonne (ASSEMB.H)
=PIVOTER.PAR(
Tableau1[[#Tout];[Contrat]];
;
Tableau1[[#Tout];[Salaire]];
ASSEMB.H(NBVAL;MOYENNE))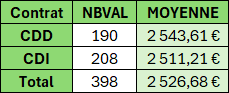
En vertical/ligne (ASSEMB.V)
=PIVOTER.PAR(
Tableau1[[#Tout];[Contrat]];
;
Tableau1[[#Tout];[Salaire]];
ASSEMB.V(NBVAL;MOYENNE))
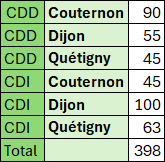
Disposition globale
Nous obtenons une disposition qui correspond à la disposition sous forme Tabulaire des tableaux croisés (sans sous-totaux).
Les dispositions en forme Compactée et Plan ne sont pas réalisable.
=PIVOTER.PAR(
ASSEMB.H(
Tableau1[[#Tout];[Contrat]];
Tableau1[[#Tout];[Ville]]);
;
Tableau1[[#Tout];[Salaire]];
NBVAL)Résultat obtenu
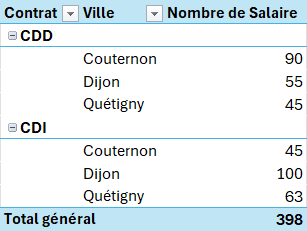
Rappel : Dispositions des tableaux croisés dynamique.
Forme Tabulaire

Forme Compactée (non réalisable)

Forme Plan (non réalisable)
Mise en forme du tableau
La fonction PIVOTER.PAR renvoyant l'ensemble du tableau, la mise en forme est assez problématique.
Elle peut être faite :
- Manuellement : Mais doit être refaite si le tableau se propage plus/moins lors de sa mise à jour.
- Automatiquement : Nécessite de nombreuses Mise en forme conditionnelles plus ou moins complexe.
=PIVOTER.PAR(
ASSEMB.H(
Tableau1[[#Tout];[Contrat]];
Tableau1[[#Tout];[Service]]);
ASSEMB.H(
Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Classification]]);
Tableau1[[#Tout];[Matricule]];
NBVAL;;2)Mise en forme par des mises en forme conditionnelles
Exemple de rendu

Mises en forme conditionnelles appliquées

Par exemple, une règle pour :
- Les bordures,
- La ligne de titre,
- Les lignes de sous-totaux,
- La ligne de Total général,
- ...
Remarques
- La plage d'application ne peut pas être prévue et donc doit être prise avec une marge suffisante.
Ceci obligera parfois à ajouter des tests d'existences de contenu du type C$2<>"". - La répétition des titres peut être masquée en donnant au texte la même couleur que le fond.
- Les sous-totaux peuvent être repérés par l'absence d'étiquette du champ de droite sur la ligne correspondante ($C4="").
Création de regroupements personnalisés
Pour les valeurs de type Date
Par exemple, regrouper les données par année et mois de naissance.
=PIVOTER.PAR(
ASSEMB.H(
ANNEE(Tableau1[[#Tout];[Naissance]]);
MOIS(Tableau1[[#Tout];[Naissance]]));
;
Tableau1[[#Tout];[Matricule]];
NBVAL)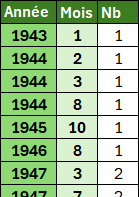
Pour les valeurs de type Numérique
Par exemple, regrouper les données par tranche de 1 000 € de salaire.
On génère les bornes des plages en faisant des arrondis au multiple (ici 1 000).
=PIVOTER.PAR(
PLANCHER.MATH(Tableau1[[#Tout];[Salaire]];1000) & "-" & PLAFOND.MATH(Tableau1[[#Tout];[Salaire]];1000);
;
Tableau1[[#Tout];[Matricule]];
NBVAL)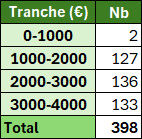
Remarque : Les étiquettes de colonne ont été ici ajoutées manuellement.
Pour les valeurs de type Alphanumérique (le texte)
Par exemple, regrouper les données par pôle regroupant plusieurs services.
=LET(
Support;ESTNUM(EQUIV(Tableau1[[#Tout];[Service]];{"Accueil";"Achats";"laboratoire";"Réparation"};0));
RH;ESTNUM(EQUIV(Tableau1[[#Tout];[Service]];{"Accueil";"Comptabilité";"Direction";"Personnel"};0));
Service2;SI(Support;"Support";SI(RH;"RH"; Tableau1[[#Tout];[Service]]));
Service; Tableau1[[#Tout];[Service]];
PIVOTER.PAR(
ASSEMB.H(Service2;Service);
;
Tableau1[[#Tout];[Matricule]];
NBVAL))Principe :
- Via les variables Support et RH (fonction LET), on identifie l'appartenance du service aux pôles.
- EQUIV renvoie la position (un numérique) si le service est trouvé sinon #N/A.
- ESTNUM nous permet d'obtenir une matrice de booléen (VRAI si position, FAUX si #N/A).
- La variable Service2 convertit les VRAI en étiquette "Support" ou "RH".

Remarque : L'affichage de la 2eme colonne d'étiquette n'est pas obligatoire (laissée ici pour exemple).
Les fonctions de synthèses
Les fonctions SOMME, NBVAL, MOYENNE, MAX, MIN, ECARTYPE.STANDARD, ECARTYPE.PEARSON, VAR.S, VAR.P.N des tableaux croisés dynamiques sont déjà présentes.
Nous disposons en plus de NB, MEDIANE, PRODUIT, POUCENTAGE.DE, CONCAT, TABLEAU.EN.TEXTE, MODE.SIMPLE.
Il manque la fonction "cachée" Total distinct/Comptage de valeurs (dénombrement sans les doublons). Pour l'obtenir dans les tableaux croisés dynamiques il faut utiliser le modèle de données.
Pour faire cette synthèse avec la fonction PIVOTER.PAR, il faut créer une fonction LAMBDA (Voir Les bases de la fonction LAMBDA).
Exemple : Nombre de Nom différents par ville (ignorer les doublons/homonymes).
=PIVOTER.PAR(
Tableau1[[#Tout];[Ville]];
;
Tableau1[[#Tout];[Nom]];
LAMBDA(v;NBVAL(UNIQUE(v)));3)
Simulation des modes d'affichage des valeurs
Je vous propose de simuler les modes suivants :
- % du total général,
- % du total de la colonne,
- % du total de la ligne,
- % de,
- Différence par rapport,
- Différence en % par rapport,
- % du total du parent,
- % du total de la ligne parente,
- % du total de la colonne parente,
- Résultat cumul par,
- % résultat cumulé dans,
- Rang - Du plus petit au plus grand,
- Rand - Du plus grand au plus petit.
Le dernier mode me semble réalisable mais je vous laisse le plaisir de le générer 😊 :
- Index.
Pourcentage du total de la colonne
Pour les valeurs numériques
Exemple : Pourcentage du nombre d'enfants en fonction de la Ville et par type de Contrat (piège classique : Nombre d'enfants, c'est ici la SOMME de la colonne Nb_enfants et non le nombre de valeurs de cette colonne).
=PIVOTER.PAR(
Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Contrat]];
Tableau1[[#Tout];[Nb_Enfants]];
POURCENTAGE.DE;3)
Pour les valeurs alphanumériques
Exemple : Pourcentage du nombre de personne en fonction de la Ville et par type de Contrat.
=PIVOTER.PAR(
Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Contrat]];
ESTTEXTE(Tableau1[[#Tout];[Nom]])*1;
POURCENTAGE.DE;3)Via ESTTEXTE on remplace le texte par du booléen puis on le convertit en numérique (*1).

Pourcentage du total de la ligne
MAJ 05/2024 : L'arguments Relative_to à 1 permet facilement ce résultat.
Exemple : Pourcentage du nombre d'enfants en fonction du Contrat et par Ville.
=TRANSPOSE(PIVOTER.PAR(
Tableau1[[#Tout];[Contrat]];
Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Nb_Enfants]];
POURCENTAGE.DE;3))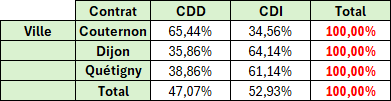
Remarque : pour de l'alphanumérique, passer par ESTTEXTE(...)*1 comme pour la version colonne.
Pourcentage du total général
MAJ 05/2024 : L'arguments Relative_to à 2 permet facilement ce résultat.
Pour les valeurs numériques
Exemple : Pourcentage du nombre d'enfants en fonction de l'ensemble des enfants, par type de Contrat et par Ville.
=PIVOTER.PAR(
Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Contrat]];
Tableau1[[#Tout];[Nb_Enfants]]/SOMME(Tableau1[[#Tout];[Nb_Enfants]]);
SOMME;3)Principe : On passe chaque valeur Nb_enfants en % puis on en fait la Somme.
Autre solution
=LET(
tab;PIVOTER.PAR(
Tableau1[[#Tout];[Ville]];Tableau1[[#Tout];[Contrat]];
Tableau1[[#Tout];[Nb_Enfants]];
SOMME;3);
SIERREUR(tab/SOMME(Tableau1[[#Tout];[Nb_Enfants]]);tab))Principe : On divise le tableau résultat de PIVOTER.PAR par le total et on intercepte les erreurs liées aux étiquettes avec SIERREUR ou un SI(ESTNUM(...)...).
Pour les valeurs alphanumériques
Exemple : Pourcentage du nombre de personne en fonction de l'ensemble des personnes, par type de Contrat et par Ville.
=PIVOTER.PAR(
Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Contrat]];
ESTTEXTE(Tableau1[[#Tout];[Nom]])/NBVAL(Tableau1[Nom]);
SOMME;3)Attention : on divise par NBVAL(Tableau1[Nom]) et non NBVAL(Tableau1[[#Tout];[Nom]]) sinon l'étiquette de colonne est comptabilisée.

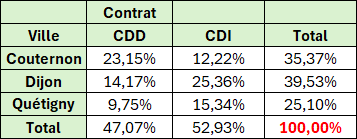
Pourcentage de (par rapport à un des éléments du tableau)
Exemple : Pourcentage du nombre de personnes en fonction de la population Dijonnaise, par type de Contrat et par Ville.
=PIVOTER.PAR(
Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Contrat]];
1/NB.SI.ENS(
Tableau1[[#Tout];[Ville]];"Dijon";
Tableau1[[#Tout];[Contrat]];Tableau1[[#Tout];[Contrat]]);
SOMME;3)Principe : On divise le nombre de personnes par le nombre de Dijonnais ayant le même type de Contrat.
Remarque :
- 1/NB.SI est préférable à ESTTEXTE(Tableau1[[#Tout];[Nom]])/NB.SI... pour les cas où des Noms sont laissés vides.
- Un étonnant NB.SI.ENS avec Tableau1[[#Tout];[Contrat]] à la fois en plage et en critère !
Différence par rapport (à un des éléments du tableau)
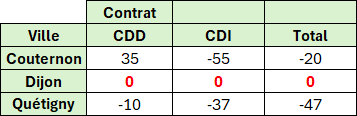
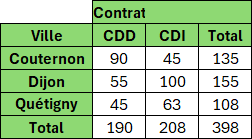
Exemple : Nombre de personnes par Ville et type de Contrat par rapport à Dijon (en plus ou en moins).
=PIVOTER.PAR(
Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Contrat]];
1-NB.SI.ENS(
Tableau1[[#Tout];[Ville]];"Dijon";
Tableau1[[#Tout];[Contrat]];Tableau1[[#Tout];[Contrat]])
/NB.SI.ENS(
Tableau1[[#Tout];[Ville]];Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Contrat]];Tableau1[[#Tout];[Contrat]]);
SOMME;3;0)Explications du résultat pour CDD/Couternon par exemple
Il y a 55 personnes en CDD à Dijon. On doit donc retirer cette valeur aux résultats de Couternon et Quetigny.
Il y a 90 personnes en CDD à Couternon.
La formule va donc faire 90 additions pour arriver au résultat (35).
La formule va être (1-55/90) + (1-55/90) +.... 90 fois (90 fois 1 donne 90 et 90 fois 55/90 donne 55).
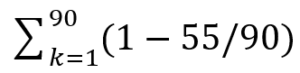
Différence en % par rapport (à un des éléments du tableau)
Exemple : Nombre de personnes par Ville et type de Contrat par rapport à Dijon (en plus ou en moins) en pourcentage.
=LET(
NbRef;NB.SI.ENS(
Tableau1[[#Tout];[Ville]];"Dijon";
Tableau1[[#Tout];[Contrat]];Tableau1[[#Tout];[Contrat]]);
PIVOTER.PAR(
Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Contrat]];
(1-NbRef/NB.SI.ENS(
Tableau1[[#Tout];[Ville]];Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Contrat]];Tableau1[[#Tout];[Contrat]]))
/NbRef;
SOMME;3;0))Explications du résultat pour CDD/Couternon par exemple
Même principe que précédemment mais le résultat sera divisé par le nombre de Dijonnais.
Cette valeur étant utilisé 2 fois, on va utiliser une fonction LET pour la mémoriser (NbRef).

% du total du parent
Exemple : Nombre de personnes par Ville, Civilité et type de Contrat en % par rapport à la ville (parent).
=PIVOTER.PAR(
ASSEMB.H(
Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Civilite1]]);
Tableau1[[#Tout];[Contrat]];
1/NB.SI.ENS(
Tableau1[[#Tout];[Ville]];Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Contrat]];Tableau1[[#Tout];[Contrat]]);
SOMME;3;2)
% du total de la ligne parente
MAJ 05/2024 : L'arguments Relative_to à 3 permet facilement ce résultat (4 pour la colonne parente).
Exemple : Nombre de personnes par Ville, Civilité et type de Contrat en % par rapport à la ville (parent).
=LET(
tab;PIVOTER.PAR(
ASSEMB.H(
Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Civilite1]]);
Tableau1[[#Tout];[Contrat]];
ESTTEXTE(Tableau1[[#Tout];[Nom]])*1;SOMME;3;2);
SIERREUR(
tab/NB.SI.ENS(
Tableau1[[#Tout];[Ville]];
SI(INDEX(tab;;2)="";"*";INDEX(tab;;1));Tableau1[[#Tout];[Contrat]];"CDD");
tab))Principe :
- On divise le tableau résultat de PIVOTER.PAR par un total et on intercepte les erreurs liées aux étiquettes avec SIERREUR ou un SI(ESTNUM(...)...).
- Ce total diviseur change en fonction de la ligne, soit le global (ville="*"), soit celui lié à la ville.

Résultat cumul par
Exemple : Nombre de personnes par Ville, Civilité et type de Contrat en valeurs cumulées par Ville.
=LET(
tab;PIVOTER.PAR(
Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Contrat]];
ESTTEXTE(Tableau1[[#Tout];[Nom]])*1;
SOMME;3);
val;N(tab);
nbl;LIGNES(val);
SI(ESTTEXTE(tab);tab;PRODUITMAT(N(SEQUENCE(nbl)>=SEQUENCE(;nbl));val)))Principe :
- Tab : Le tableau sans cumul.
- Val : Le tableau sans cumul ou les valeurs d'étiquettes sont passées à 0 (pour ne pas gêner).
- nbl : Nombre de lignes de Val.
- Si la cellule de Tab est du texte, on utilise cette valeur (étiquette) sinon on prend celle calculée à partir de Val.
- PRODUITMAT permet d'obtenir une matrice cumul des valeurs (voir image ci-dessous).
- En vert : Matrice Val.
- En rose : Matrice N(SEQUENCE(nbl)>=SEQUENCE(;nbl)).
- En blanc : Matrice résultat de PRODUITMAT.
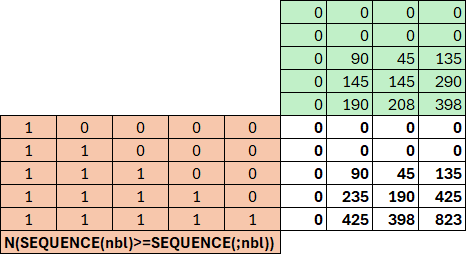
Version avec cumul
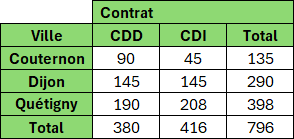
Version sans cumul (pour comparaison)
% résultat cumulé dans
Exemple : Nombre de personnes par Ville, Civilité et type de Contrat en pourcentages cumulés par Ville.
=LET(
tab;PIVOTER.PAR(
Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Contrat]];
1/NB.SI.ENS(Tableau1[[#Tout];[Contrat]];Tableau1[[#Tout];[Contrat]]);
SOMME;3);
val;N(tab);
nbl;LIGNES(val);
SI(ESTTEXTE(tab);tab;PRODUITMAT(N(SEQUENCE(nbl)>=SEQUENCE(;nbl));val)))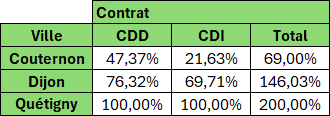
Rang - Du plus petit au plus grand / Rang - Du plus grand au plus petit
Exemple : Classement du nombre de personnes par Ville et type de Contrat en colonne (par Ville).
=LET(
Tab;PIVOTER.PAR(
Tableau1[[#Tout];[Ville]];
Tableau1[[#Tout];[Contrat]];
ESTTEXTE(Tableau1[[#Tout];[Contrat]])*1;
SOMME;3;0);
NbChpLigne; 1;
NbChpColonne; 1;
Sens; -1;
Plage;EXCLURE(Tab;NbChpColonne+1;NbChpLigne);
Class;MAKEARRAY(
LIGNES(Tab);COLONNES(Tab);
LAMBDA(r;c;
SI(ET(r>NbChpColonne+1;c>NbChpLigne);
LET(
Col;INDEX(Plage;;c-NbChpLigne);
EQUIV(
INDEX(plage;r-NbChpColonne -1;c-NbChpLigne);
TRIER(FILTRE(Col;ESTNUM(Col));;Sens);
0))
)));
SI(ESTTEXTE(Tab);Tab;Class))Principe :
- Tab : Le tableau sans classement.
- NbChpLigne : Le nombre de champs placés en étiquette de ligne.
- NbChpColonne : Le nombre de champs placés en étiquette de colonne.
- Sens : Ordre du classement.
- 1 : Du plus petit au plus grand.
- -1 : Du plus grand au plus petit.
- Plage : Le tableau sans étiquettes de ligne ou de colonne.
- Class : Tableau avec le classement des valeurs.
- Les lignes/colonnes correspondants aux étiquettes sont remplies par FAUX (Argument Valeur_Si_Faux la fonction SI non précisé car inutile).
- Génération du classement via une fonction EQUIV (la fonction EQUATION.RANG étant non utilisable).
- Les valeurs vides sont considérées comme du texte et décale le classement d'où le FILTRE pour les éliminer.
- On génère le résultat en piochant dans les étiquettes dans Tab et les valeurs dans Class.

Personnalisation étiquettes
La solution la plus simple est de passer par des mises en forme conditionnelles.
Exemple : Si la cellule est égale à "Ville" appliquer le format de nombre ;;;"Agglomération" permettant ainsi de remplacer l'étiquette Ville par Agglomération.
Utilisation des segments pour appliquer un filtre
Une solution "lourde", utilisable pour un tableau de bord.
Le principe
Le segment filtre le tableau structuré.
Via l'argument Filtre_array de la fonction PIVOTER.PAR, on ne prend en compte que les lignes visibles.
Mise en œuvre
On va ajouter une colonne (je l'ai nommée Filtre) dans la base de données permettant de savoir si la ligne est filtrée ou non.
Pour cela on va utiliser une astuce secrète !
La fonction SOUS.TOTAL est une des seules fonctions EXCEL dont le résultat change en fonction du filtre appliqué.
On va lui demander, par exemple, de compter la valeur à côté d'elle.
- Si la valeur est affichée (donc/car ligne affichée), on obtient 1.
- Si la valeur est masquée (donc/car ligne masquée), on obtient 0 (on ne peut pas voir cette valeur car la ligne la contenant est masquée 😁).
=SOUS.TOTAL(3;[@Ville])Il nous reste donc qu'a indiquer à PIVOTER.PAR de ne prendre que les lignes où Filtre est à 1.
=PIVOTER.PAR(
ASSEMB.H(Tableau1[[#Tout];[Contrat]];Tableau1[[#Tout];[Ville]]);
;
Tableau1[[#Tout];[Nom]];
NBVAL;3;;;;;
Tableau1[[#Tout];[Filtre]]=1)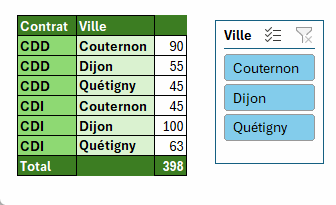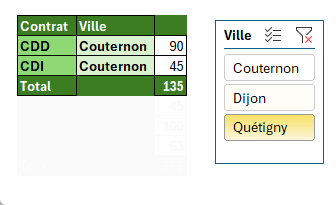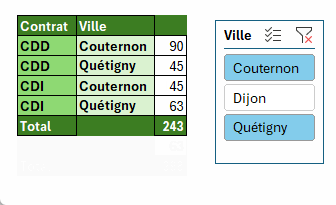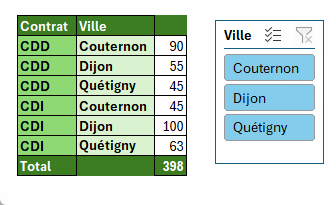
Rappel : Les segments Chronologie de sont pas utilisable (du moins pas directement 😁 voir Une chronologie (segment) pour un tableau, c'est possible !).
Divers
- PIVOTER.PAR fonctionne avec les images intégrées dans les cellules (Voir Manipuler des images comme des données).
Merci pour votre attention bienveillante.
