Windows : Disponible à partir de la version 2406 (build 17715.20000) ou ultérieure.
Maj 08/2024 : Ajout des expressions régulières aux fonctions RECHERCHEX et EQUIVX (Windows: Version 2408 (Build 17931.20000)).
Microsoft a annoncé 3 nouvelles fonctions permettant d'exploiter la puissance des expressions régulières (voir Expression régulière — Wikipédia (wikipedia.org)).
Pour résumer : Une expression régulière est une chaîne de caractères (appelée motif ou pattern en Anglais) qui décrit avec des codes les caractéristiques d'une chaîne (une sorte de portrait-robot).
Ces motifs pouvant être très complexe, on peut demander de l'aide aux AI mais penser à bien contrôler l'exactitude des réponses fournies qui sont parfois incomplètes voir fausses 😔.
On peut facilement tester nos motifs sur différents sites comme par exemple regex101: build, test, and debug regex.
Les 3 nouvelles fonctions proposées par Microsoft sont :
- REGEXTEST : Vérifie la présence d'une portion de texte, dans une chaîne, correspondant au motif de texte fourni.
- REGEXEXTRACT : Renvoie les sous chaînes de texte qui correspondent au motif fourni.
- REGEXREPLACE : Recherche les sous chaînes de texte qui correspondent au motif fourni, puis les remplace par une chaîne de remplacement.
Mémento des principales syntaxes des expressions régulières
Attention : j'ai ajouté des espaces entre les caractères des motifs pour améliorer la lisibilité.
- Les ensemble de caractères [ ] (classes).
- " [ a e i o u y x ] " : Toutes les voyelles et "x" (OU avec le pipe " a | e | i | o | u | y | x ").
- " [ 0 - 8 ] " : Tous chiffres entre 0 et 8.
- " [ e - t ] " : Tous caractère de "e" à "t" (Attention : "[ - e t ]" c'est "tiret "-" ou "e" ou "t").
- " [ E - T ] " : Tous caractère de "E" à "T" (la casse est prise en compte !).
- " [ ^ e - t ] " : Tous caractère SAUF les caractères "e" à "t".
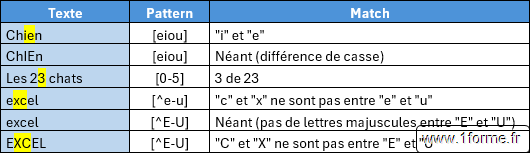
- Les raccourcis d'ensemble (La version en capital/MAJUSCULE renvoie le complément = l'inverse).
- " \ d " : Les chiffres de 0 à 9 (" [ 0 - 9 ] + ").
- " \ D " : Pas un chiffres (" [ ^ 0 - 9 ] + ").
- " \ w " : Les caractères alphanumériques et "_" (" [ a - z A - Z 0 - 9 _ ] ").
- Les caractères accentués sont bien inclus.
- " \ W " : Pas un caractère alphanumérique et pas "_" (" [ ^ a - z A - Z 0 - 9 _ ] ").
- " \ s " : Les caractères "non imprimables" (Espace, Espace insécable (Alt+0160), tabulation, retour à la ligne, retour chariot, saut de page...).
<=>" [\r\n\t\f\v] ". - " \ S " : Pas un caractère "non imprimables".
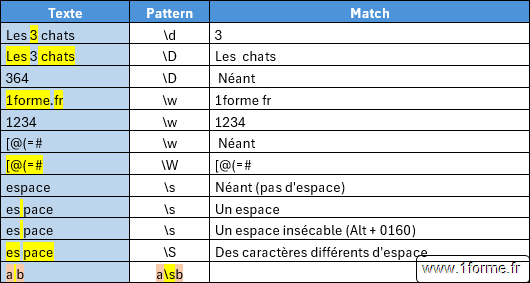
- Caractère.
- " . " : Tous caractères (Piège : Lors de la saisie de 3 "." consécutifs, ils peuvent être remplacés par le caractère unique Points de suspension "..." par l'outil Correction automatique !).
- " a " : Le caractère "a".
- " \ t " : Le caractère Tabulation.
- " \ n " : Le caractère Retour/saut à la ligne.
- " \ N " : Pas le caractère Retour/saut à la ligne.
- " \ r " : Le caractère Retour chariot.
- " \ f " : Le caractère Saut de page.
- " \ h " : Un caractère "vide" (Espace, Espace insécable (Alt+0160), tabulation).
- " \ H " : Pas un caractère "vide".
- " \ " Caractère d'échappement (pour rechercher un des caractères suivant ^ $ \ | { } [ ] ( ) ? + * . ) # ! <=> " a \ + " : chaîne " a+ " et non un ou plusieurs "a".
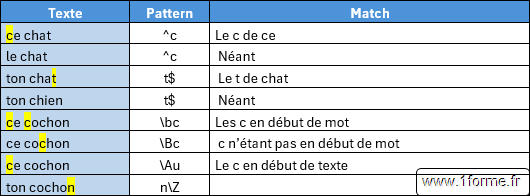
- Condition de position dans la chaîne.
- " ^ " : Normalement Début de ligne mais semble être Début de chaîne (" \ A ") .
- " $ " : Fin de ligne.
- " \ b " : Début et fin de mot.
- " \ B " : Pas en début et fin de mot.
- " \ A " : Début de chaîne.
- " \ Z " ou " \ z " : Fin de chaîne.
- Les quantificateurs de caractères
- " a { 3 } " : 3 fois le caractère "a" ("aaa").
- " a { 2 , 4 } " : Entre 2 et 4 caractères "a" successifs ("aa" ou "aaa" ou "aaaa").
- " a { 2 , } " : Au moins 2 caractères "a" successifs ("aa" ou "aaa" ou "aaaa" ou ...).
- " a ? " : Zéro ou un "a" ( =" a { , 1 } ").
- " a * " : Zéro ou plusieurs "a" ( = " a { 0 , } ").
- " a + " : Un ou plusieurs "a" ( = " a { 1 , } ").
Une petite finesse à voir :
- Comportement "Greedy" (Gourmand)
- Comportement par défaut des quantificateurs "*" et "+".
- Il cherche à capturer la plus longue chaîne de caractères possible qui correspond au motif (prend le maximum).
- Exemple : "Au début le finaud biffin ri" => "début.*fin" => "début le finaud biffin".
- Comportement "Lazy"
- Il cherche alors à capturer la chaîne de caractères la plus courte possible qui correspond au motif (prend le minimum).
- Pour rendre un quantificateur "Lazy", on ajoute un point d'interrogation (?) juste après lui ("*?", "+?").
- Exemple : "Au début le finaud biffin ri" => "début.*?fin" => "début le fin".

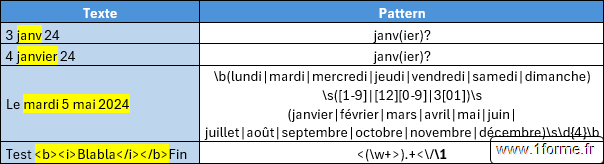
- Les groupements ( )
Identifier une portion afin d'étendre ou restreindre son application ou afin d'y faire référence.- " ( a | b ) c " : "ac" ou "bc".
- " a( 0 1 ) + a " : "a01a" ou "a0101a" ou "a010101a"...
- "( ) \ 1 " : Référence au 1er regroupement.
- Les Lookarounds testent la présence ou l’absence d’un motif juste avant ou juste après le motif cherché.
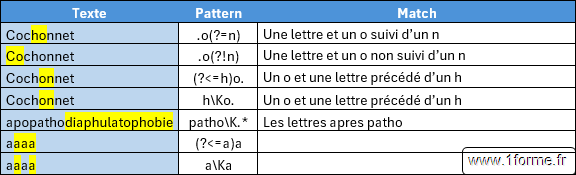
- " a ( ? = b ) " : Les " a " suivis d'un "b".
- " a ( ? ! b ) " : Les " a " non suivis d'un "b".
- " ( ? < = b ) a " ou " b \ K a " : Les " a " qui succède à un "b".
- " b \ K a " : Autre solution moins souple pour les " a " qui succède à un "b" ("Cherche "b" comme position de départ puis commence la recherche de "a").
- Mode récursif
- " a ( ? R ) ? b " : Une chaîne de "a" suivit d'autant de "b" (ab, aabb, aaabbb...).
( ? R ) reprend le motif en entier.
<=> " a ( a ( a....) ? b ) ? b" - " a ( ? 0 ) ? b " : idem
- " a \ g < 0 > ? z " : idem
\g<0> : Référence arrière au groupe de capture 0 (sous chaîne qui correspond au motif jusqu’à ce point).
- " a ( ? R ) ? b " : Une chaîne de "a" suivit d'autant de "b" (ab, aabb, aaabbb...).
- Codage Unicode
- " \ x { 221E } " : Le caractère ayant le code 221E (∞).
- " \ p { N } " : La catégorie des chiffres (comme " \ d ").
- " \ P { N } " : Pas de la catégorie des chiffres (comme " \ D ").
- " \ p { L } " : La catégorie des lettres.
- " \ P { L } " : Pas de la catégorie des lettres.
- " \ p { Lu } " : La catégorie des lettres capitales ("majuscule", u pour upper).
- " \ P { Lu } " : Pas de la catégorie des lettres capitales.
- " \ p { Ll } " : La catégorie des lettres minuscules ( l pour lower).
- " \ P { Ll } " : Pas de la catégorie des lettres minuscules.
- " \ p { P } " : Catégorie des signes de ponctuations (virgule, guillemet...).
- Remarques :
- " \ w " = [ \p{Ll} \p{Lu} \p{Lt} \p{Lo} \p{Lm} \p{Mn} \p{Nd} \p{Pc} ]
- J'ai omis plusieurs codes me semblant trop spécifiques.
Exemple : \p{Lt} pour les caractères de casse de titre comme Dž (U01C5).
Pour Lt, Lo, Lm, Mn, Me... voir Catégories de caractères Unicode (compart.com)
- Sensibilité à la casse
Les fonctions Excel possèdent directement un argument permettant de gérer ce paramètre globalement mais il est possible de le faire via des flags (inline)- " (?i) " : Active l'insensibilité pour la suite du pattern.
Exemple :- "(?i)Vente" correspond à "vente", "VENTE", "Vente", "VeNtE".
- " (?-i)" : Désactive l'insensibilité pour la suite du pattern.
Exemple :- "(?i)v(?-i)ente" correspond à "vente", "Vente" (peut être que "[Vv]ente" aurait suffit 😁?).
- " (?i) " : Active l'insensibilité pour la suite du pattern.
Je pense que c'est déjà suffisant pour un résumé 😁.
Exemples de motifs :
Attention : les motifs trouvés sur internet sous souvent plus ou moins complet/précis (oublie de cas particuliers).
- Carte de crédits (trouvées sur internet et non vérifiées).
- Visa : " ^4[0-9]{12}(?:[0-9]{3})?$ "
- MasterCArd : " ^(?:5[1-5][0-9]{2}|222[1-9]|22[3-9][0-9]|2[3-6][0-9]{2}|27[01][0-9]|2720)[0-9]{12}$ "
- American Express : " ^(?:5[1-5][0-9]{2}|222[1-9]|22[3-9][0-9]|2[3-6][0-9]{2}|27[01][0-9]|2720)[0-9]{12}$ "
- Adresse mail
- Versions simples (trouvées sur internet et non vérifiées)
- "^[\w.=-]+@[\w.-]+.[\w]{2,64}$" (Expressions régulières pour débutants (netwrix.fr)).
- "^([\w-!#$%&'+/=?^
{|}~.]+)@[\w\-!#$%&'*+/=?^_{|}~.]+(.[\w-!#$%&'+/=?^`{|}~.]+)*(.[a-z]{2,64})$". - Il semble qu'il soit impossible de générer une expression répondant parfaitement aux normes et que celle s'en approchant sont complexes et demandent beaucoup de ressources systèmes.
- Versions simples (trouvées sur internet et non vérifiées)
- Une plage IP de l'IP 192.168.11.0 à 192.168.12.255 : " 192\.168\.(11|12)\..* " (version simple sans contrôle de la validité de la dernière plage).
- Points absents en fin de ligne : " [^.]$ "
Fonction REGEXTEST
Rôle
Vérifier la présence d'une portion de texte dans une chaîne, correspondante à un motif de texte, en renvoyant TRUE ou FALSE.
Utilisations
- Avec la fonction FILTRE.
- Avec l'outil Mise en forme conditionnelle.
- Avec l'outil Validation de données.
Syntaxe
=REGEXTEST( text ; pattern ; [case_sensitivity] )Arguments
- Text : Texte ou cellule à tester.
- Pattern : Motif/expression régulière correspondant au texte à chercher dans Text.
- case_sensitivity :
- [ 0 ] : Valeur par défaut, différencie les caractères en capital (MAJUSCULES) des caractères minuscules.
- 1 : Pas de différence entre caractères capital et caractères minuscules.
Exemples
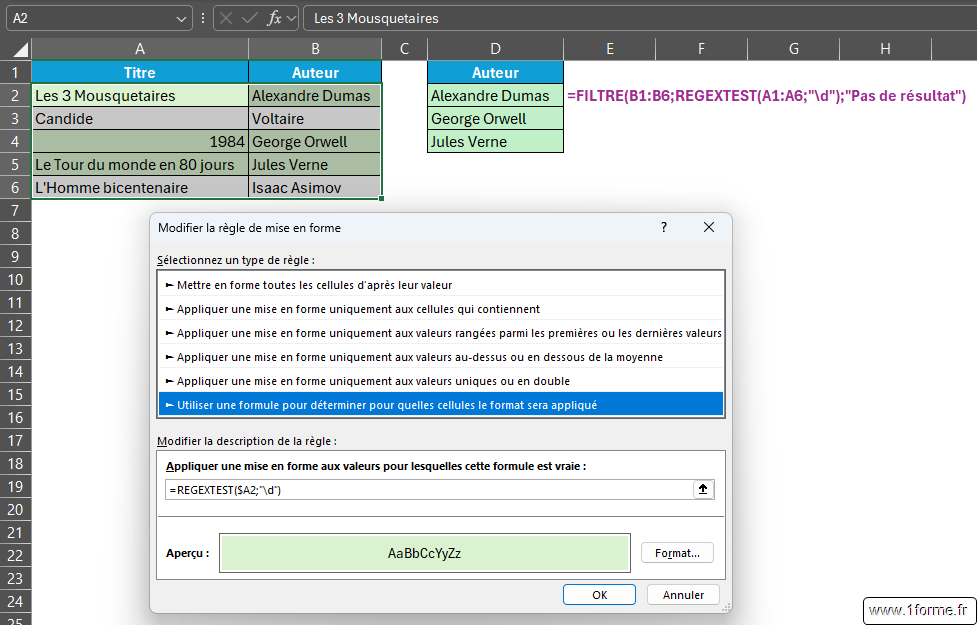
Est-ce la cellule B5 contient un chiffre ?
B5 = "Les 3 chats"
=REGEXTEST( B5 ; "\d" ) => VRAI
B5 = "Les trois chats"
=REGEXTEST( B5 ; "\d" ) => FAUXMise en œuvre avec la fonction FILTRE et dans une mise en forme conditionnelle.
Fonction REGEXEXTRACT
Rôle
Extraire une ou des portions de texte, dans une chaîne, correspondant à un motif de texte fourni. Si aucune correspondance n'est trouvée la fonction renvoie #N/A.
Syntaxe
=REGEXEXTRACT( text; pattern ; [return_mode] ; [case_sensitivity] )Argument spécifique
- return_mode : Type/nombre de valeurs retournées.
- [ 0 ] : Valeur par défaut, 1ere occurrence.
- 1 : Tableau de toutes les occurrences.
- 2 : Tableau des groupes de la 1ère occurrence.
Exemple 1 (return_mode à 0 et à 1)
Décomposer un texte par mots.
=REGEXEXTRACT( "Un beau chat" ; "\b\S+" ; 0 ) => "Un"
=REGEXEXTRACT( "Un beau chat" ; "\b\S+" ; 1 )
=> Une table dynamique de 3 lignes contenant
"Un"
"beau"
"chat"Exemple 2 (return_mode à 0 et à 2)
Renvoyer le texte entre les guillemets.
B5 = "Le "beau" chien"
=REGEXEXTRACT( B5 ; """.*""" ; 0 ) => ""beau"" (Les guillemets sont renvoyés)
=REGEXEXTRACT( B5 ; """(.*)""" ; 2 ) => "beau" (Texte sans guillemets)Fonction REGEXREPLACE
Rôle
Remplacer une ou des portions de texte, dans une chaîne, correspondant à un motif de texte par une autre chaîne de texte. Si aucune correspondance n'est trouvée la fonction renvoie #N/A.
Syntaxe
=REGEXREPLACE( text; pattern ; replacement ; [occurrence] ; [case_sensitivity] )Arguments spécifiques
- replacement : Texte de remplacement ou référence au groupe de capture.
- occurrence :
- [ 0 ] : Valeur par défaut, toutes les instances trouvées.
- 1, 2, 3 .... la 1ere, 2eme, 3eme ... instance à partir du début.
- -1, -2, -3 .... la 1ere, 2eme, 3eme ... instance à partir de la fin.
Exemple 1
Supprimer les répétitions.
=REGEXREPLACE("Il fait fait beau ce ce matin";"\b(\w+)\s+\1\b";"$1") => "Il fait beau ce matin"Exemple 2
Inverser des noms (en capitales) et le/les prénoms.
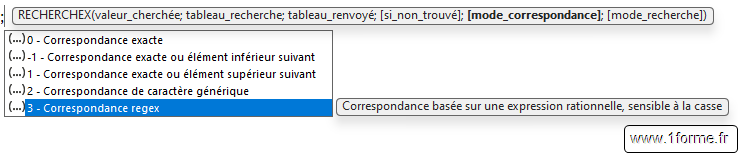
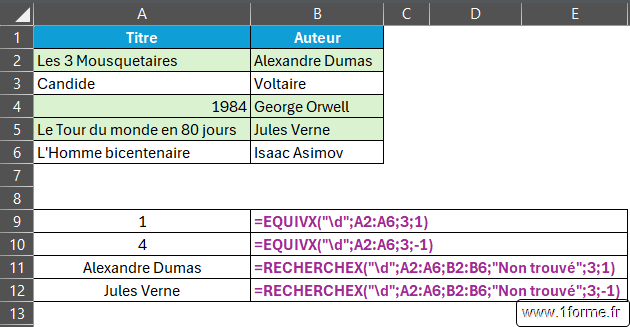
=REGEXREPLACE("DUPONT Jean Luc";"([A-Z]+)\s(.*)";"$2 $1") => "Jean Luc DUPONT"Intégration à RECHERCHEX et EQUIVX
Un nouveau mode de correspondance a été ajouté à ces fonctions permettant l'exploitation des expressions régulières.
Exemples d'utilisation
Merci pour votre attention bienveillante.